




11. diel - Pandas - Kombinovanie DataFrame Nové
V minulej lekcii, Pandas - Matematické a štatistické metódy, sme si ukázali niektoré matematické metódy a štatistické metódy.
V tomto tutoriále knižnice Pandas v Pythone sa zameriame
na metódy, ktoré nám pomáhajú efektívne kombinovať
dataframe. Ukážeme si metódy ako concat(),
merge(), join() alebo update().
Kombinovanie DataFrame v Pandas
Než si predstavíme dnešnú tému, poďme si najskôr importovať testovacie dáta.
Import dát
Rovnako ako v lekcii - Pandas - Metódy pre výber, radenie a analýzu dát, použijeme dataset s úbytkom zamestnancov v zdravotníckom sektore v USA. Dataset je opäť dostupný v prílohe na konci lekcie.
Naimportujeme si dáta:
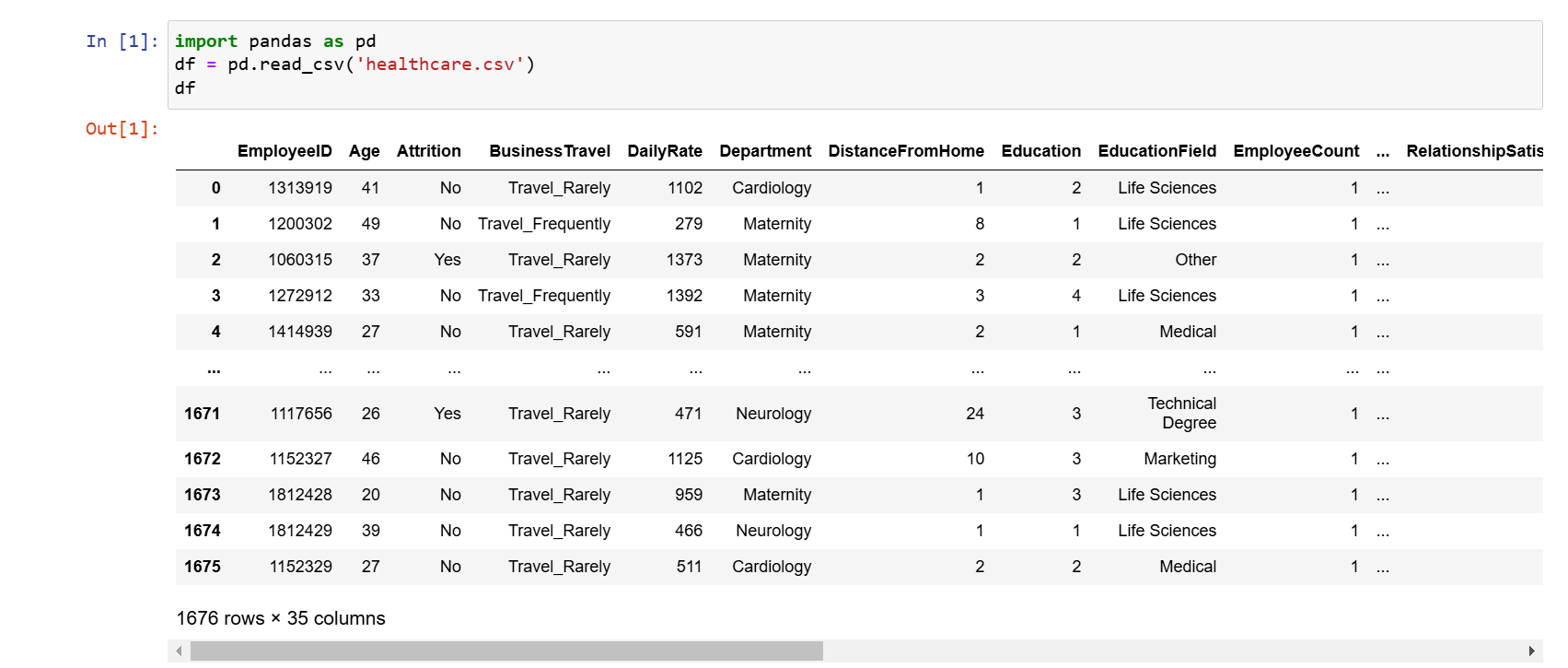
import pandas as pd df = pd.read_csv('healthcare.csv') df
Výsledok importu dát je nasledujúci:
Metódy
Kombinovanie dát je kľúčovou súčasťou analýzy, najmä ak pracujeme s rôznymi zdrojmi dát alebo potrebujeme obohatiť existujúci dataset o ďalšie informácie. Ukážeme si metódy, ktoré nám kombinovanie týchto dát umožňujú.
concat()
Metóda concat() umožňuje spojiť niekoľko dataframov
pozdĺž riadkov alebo stĺpcov. Spájanie
prebieha bez ohľadu na spoločné kľúče alebo indexy.
Vyberieme si zamestnancov z dvoch oddelení - Cardiology a
Neurology:
cardiology = df[df['Department'] == 'Cardiology'] neurology = df[df['Department'] == 'Neurology']
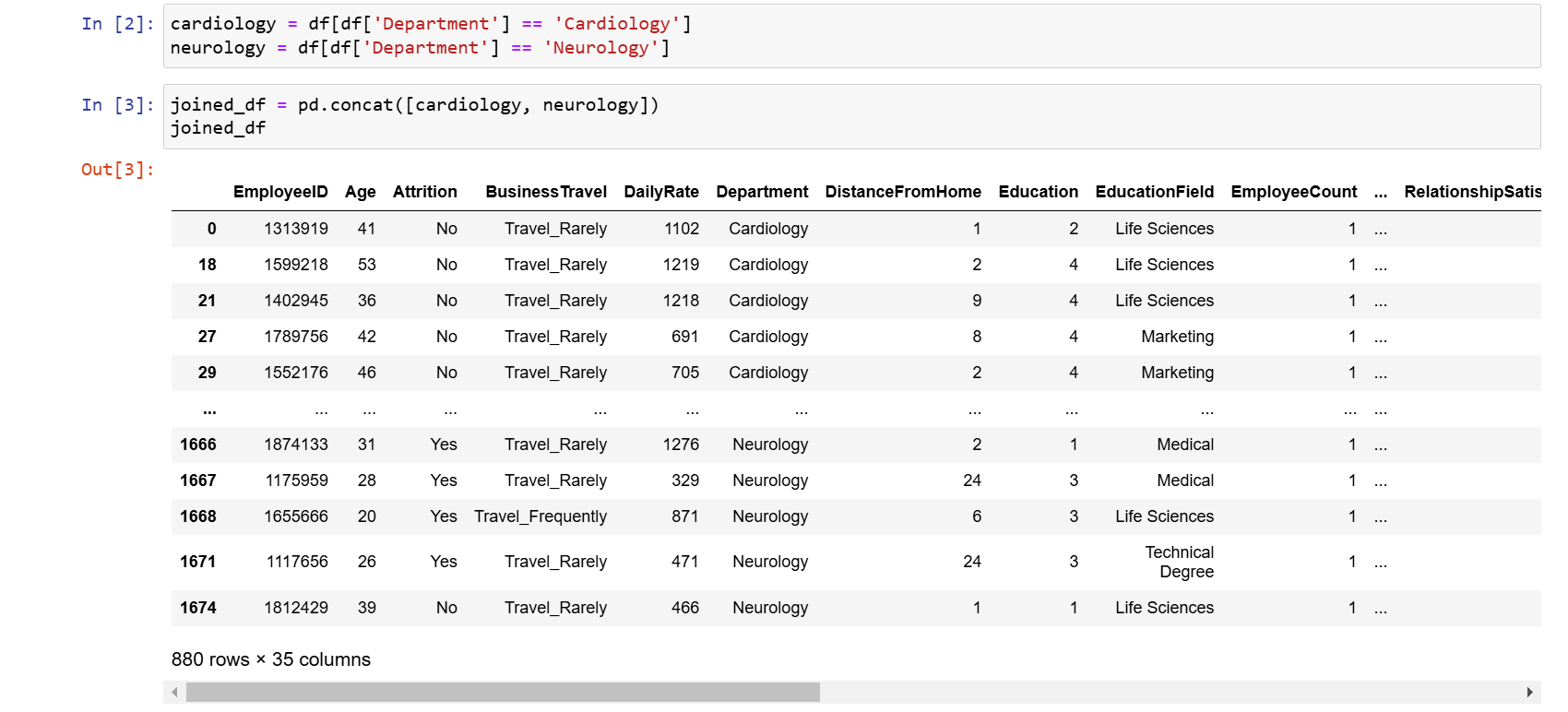
Tieto dva dataframy teraz spojíme dohromady:
joined_df = pd.concat([cardiology, neurology]) joined_df
Vznikol nám dataframe so zamestnancami z oboch oddelení:
merge()
Pomocou metódy merge() zlúčime dva dataframy na základe
spoločných stĺpcov alebo indexov. Možnosti
pre spájanie dát určuje parameter how.
Parameter how
Parameter how prijíma niekoľko hodnôt:
left: Zachová všetky riadky z ľavého dataframu a zodpovedajúce riadky z pravého dataframu. Pokiaľ nie je nájdená zhoda, vyplní hodnotouNaN.right: Zachová všetky riadky z pravého dataframu a zodpovedajúce riadky z ľavého dataframu. Pokiaľ nie je nájdená zhoda, vyplní hodnotouNaN.inner: Zachová iba riadky so zodpovedajúcimi hodnotami v oboch dataframoch. Riadky bez zhody sú vyradené.outer: Zachová všetky riadky z oboch dataframov. Riadky bez zodpovedajúcej hodnoty v druhom dataframe sú vyplnené hodnotouNaN.
Tvorba nového dataframe
Vyskúšame si teraz prácu s merge(). Najprv si vytvoríme
nový dataframe, ktorý bude obsahovať iba
EmployeeID a nový stĺpec PreferredTransport:
transport = {
'EmployeeID': [1414939, 1200302, 1060315, 1812428, 1313919],
'PreferredTransport': ['Car', 'Bike', 'Public Transport', 'Walk', 'Car']
}
df_transport = pd.DataFrame(transport)
Stĺpec EmployeeID bude slúžiť ako spojenie medzi
dvoma dataframami. Vytvorili sme päť záznamov s hodnotami
EmployeeID reálnych zamestnancov z nášho datasetu. V stĺpci
PreferredTransport sa bude nachádzať preferovaný spôsob dopravy
do práce.
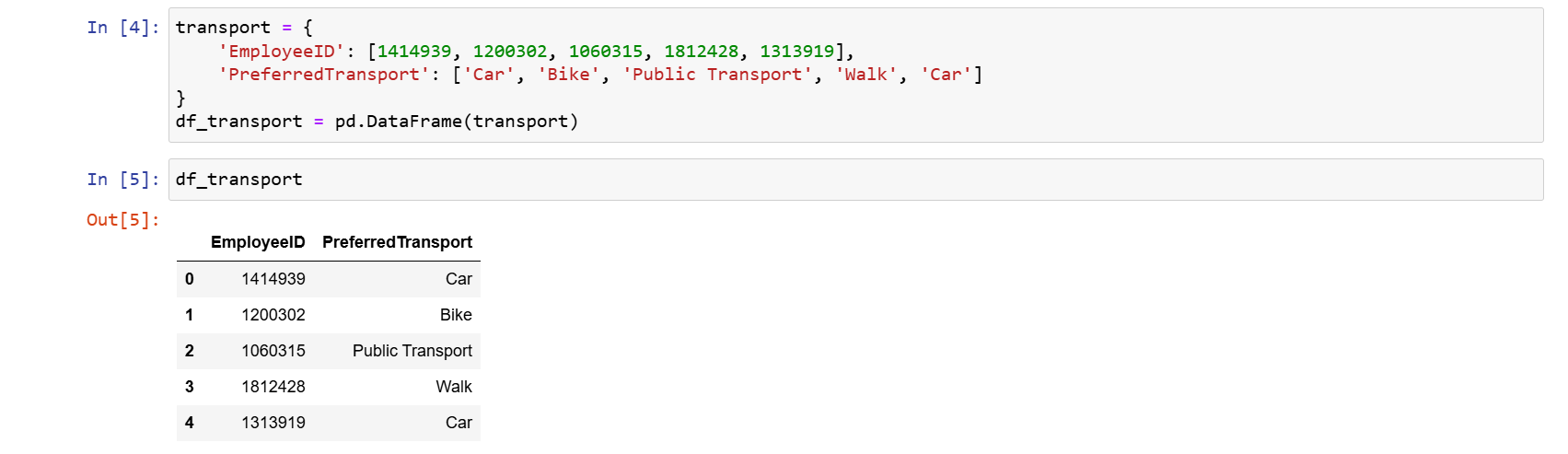
Teraz si tento nový dataframe zobrazíme:
df_transport
Po spustení kódu vidíme:
Hodnota left v parametri
how
Metódu merge() si teraz vyskúšame s vložením hodnoty
left do parametra how:
merged_df = pd.merge(df, df_transport, on='EmployeeID', how='left') merged_df[['EmployeeID', 'PreferredTransport', 'Age']]
Výstupom bude opäť nový dataframe, ktorý však obsahuje spojenie dvoch
dataframov - df a df_transport. Pri využití
merge() sme postupne v parametroch on a
how odovzdali oba dataframy.
Parameter on určuje stĺpec na ktorom oba
dataframy prepájame a parameter how spôsob, akým prepájame.
Zobrazené dáta teraz vyzerajú takto:
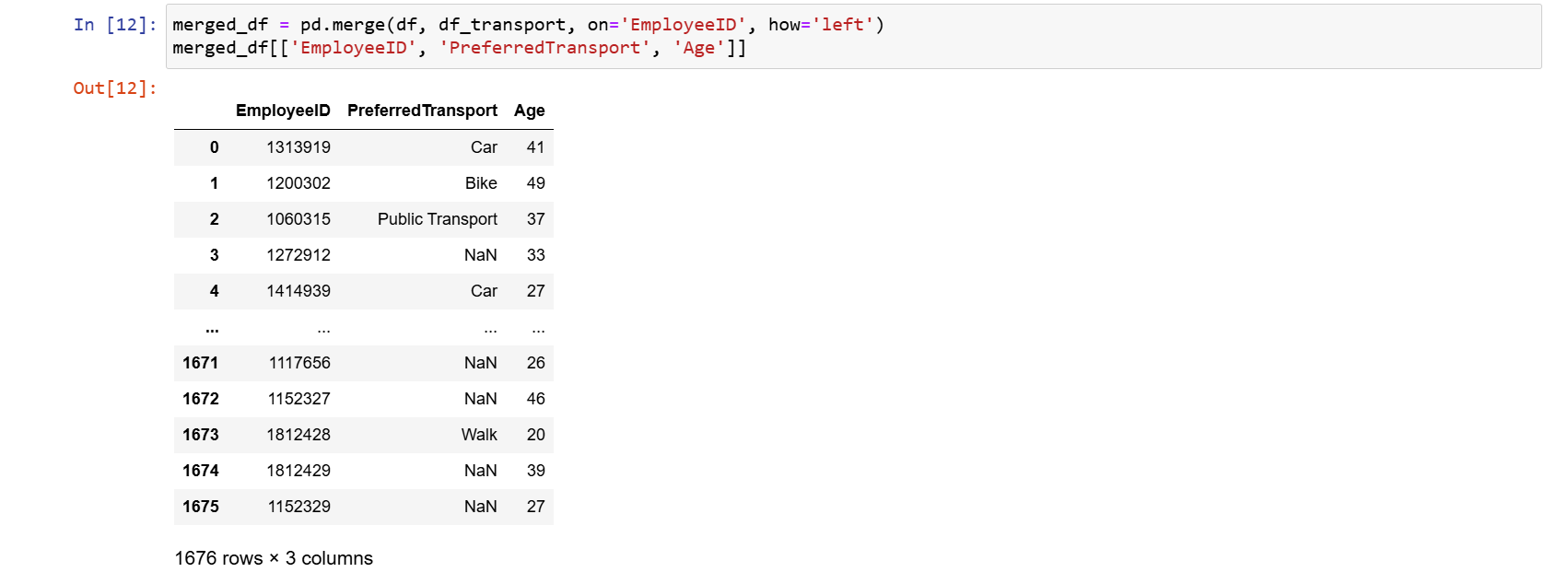
Všimnime si, že nie všetky hodnoty sa vyplnili. Dôvodom je, že sme
použili spôsob prepojenia left. Použili sa tak dáta z dataframu
df a zhoda sa nenašla všade, preto väčšina dát má hodnotu
NaN.
Hodnota inner v parametri
how
Vyskúšajme si teraz to isté, ale s využitím hodnoty inner.
Zmeňme si ešte názov premennej dataframe na merged_df_inner (ten
pôvodný budeme ešte potrebovať):
merged_df_inner = pd.merge(df, df_transport, on='EmployeeID', how='inner') merged_df_inner[['EmployeeID', 'PreferredTransport', 'Age']]
Dostaneme teraz iba zamestnancov, kde sa podarilo prepojenie:

join()
Metóda join() nám umožní spojiť dva dataframy
podľa indexov. Je všeobecne jednoduchšie na použitie ako
merge() a vhodné, ak chceme pridať ďalšie stĺpce na základe
zhodných indexov.
Pripojme si informácie o firemnom členstve zamestnancov v klube zdravia.
Klub zdravia bude charakterizovaný stĺpcom HealthClubMembership,
ktorý bude uložený v samostatnom dataframe:
health_club_data = {
'HealthClubMembership': ['Yes', 'No', 'Yes', 'No', 'Yes']
}
df_health_club = pd.DataFrame(health_club_data).set_index(neurology.index[:5])
Dataframu df_health_club sme nastavili správne
indexy využitím metódy set_index(). Indexy sme vybrali
ako prvých päť indexov z dataframu neurology.
Následne pomocou metódy join() vytvoríme nový dataframe
prepojený s dataframom neurology:
joined_df = neurology.join(df_health_club) joined_df[['EmployeeID','Age','HealthClubMembership','Department']].head(7)
Výstupom bude prvých sedem zamestnancov z oddelenia neurology
spoločne s informáciou, či sú v klube zdraví alebo nie:
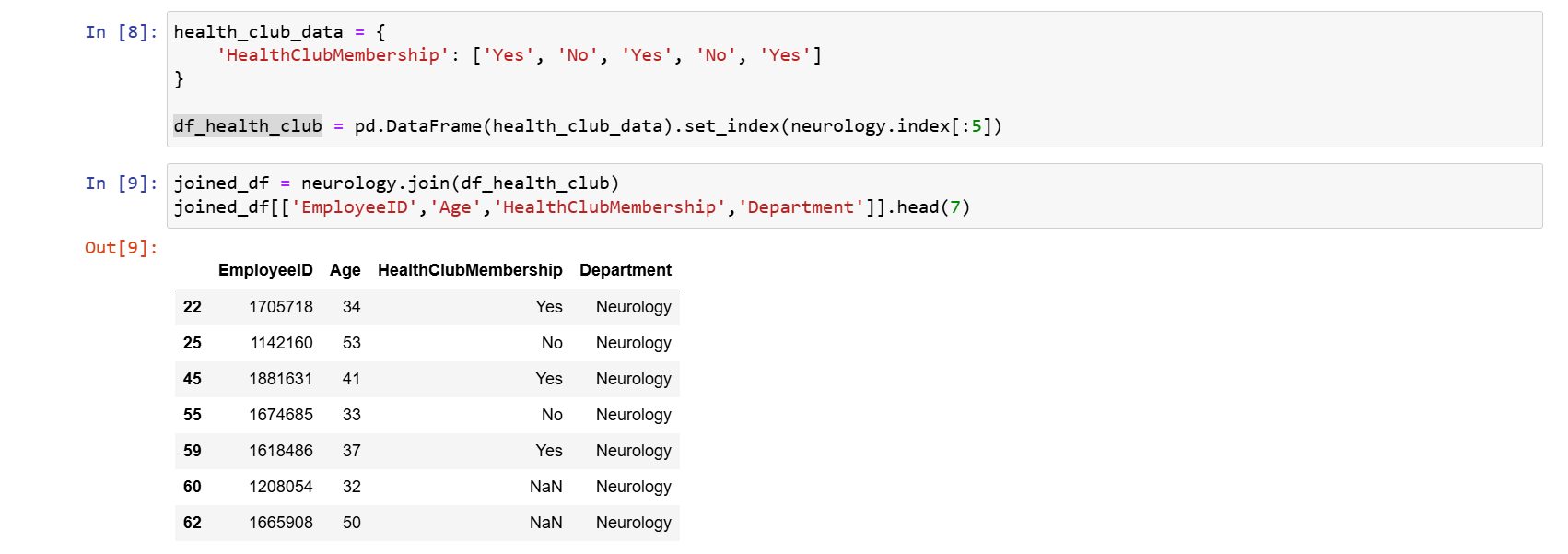
Nenájdený index sa opäť vyplní hodnotou
NaN.
combine_first()
Metóda combine_first() sa používa na doplnenie
chýbajúcich hodnôt v jednom dataframe hodnotami z iného
dataframu. Pri použití sa zachová štruktúra prvého dataframu, ale
kombinujú sa dostupné informácie z oboch dataframov.
Vyskúšame si teraz metódu combine_first() na doplnenie
niekoľkých hodnôt, ktoré sme nevyplnili pri použití merge() v
stĺpci PreferredTransport. Zobrazíme si najskôr znovu tento
dataframe:
merged_df[['EmployeeID', 'PreferredTransport', 'Age']].head(10)
Dostaneme tento výstup:

Zobrazili sme si prvých desať riadkov. Vidíme, že niektoré riadky majú
hodnotu NaN. Tento problém teraz vyriešime.
Najprv si pripravíme dáta a z nich vytvoríme dataframe:
transport = {
'PreferredTransport': [None, None, None, 'Public Transport', None, 'Car','Bus','Plane','Walk','Bike']
}
df_transport = pd.DataFrame(transport)
Následne dataframu merged_df nastavíme pre stĺpec
PreferredTransport hodnoty z dataframu df_transport
využitím metódy combine_first a zobrazíme prvých desať
riadkov:
merged_df['PreferredTransport'] = merged_df['PreferredTransport'].combine_first(df_transport['PreferredTransport']) merged_df[['EmployeeID', 'PreferredTransport', 'Age']].head(10)
Vo výsledku teda dostaneme náš pôvodný dataframe merged_df
rozšírený o nové hodnoty, ktoré boli doplnené podľa indexu:

V našich dátach transport sme nastavili niektoré
hodnoty PreferredTransport na None. Všimnime si, že
táto zmena neprebehla, pretože metóda combine_first() doplní
iba prázdne hodnoty.
update()
Pomocou metódy update() môžeme aktualizovať
hodnoty v jednom dataframe na základe iného dataframu. Poďme si to
vyskúšať a aktualizovať mesačné platy a vek pre zamestnancov z oddelenia
Cardiology. Najprv sa pozrime, ako vyzerá prvých päť
zamestnancov:
cardiology[['Age','MonthlyIncome']].head()
Výsledok:

Upravíme teraz zamestnancov na indexoch 0 a 29.
Pripravíme si dáta a vytvoríme z nich dataframe:
updated_data = {
'Age': [42,47],
'MonthlyIncome': [6050, 19000]
}
updated_df = pd.DataFrame(updated_data, index=[0, 29])
Museli sme správne nastaviť indexy, pretože podľa nich bude
update() prebiehať.
Nakoniec zavoláme metódu update() a zobrazíme opäť
dáta:
cardiology.update(updated_df) cardiology[['Age','MonthlyIncome']].head()
Výsledkom bude zostarnutie dvoch zamestnancov a zvýšenie ich platu:

V nasledujúcej lekcii, Pandas - Spracovanie chýbajúcich hodnôt, si ukážeme užitočné metódy na spracovanie chýbajúcich hodnôt v dátach.
Mal si s čímkoľvek problém? Stiahni si vzorovú aplikáciu nižšie a porovnaj ju so svojím projektom, chybu tak ľahko nájdeš.
Stiahnuť
Stiahnutím nasledujúceho súboru súhlasíš s licenčnými podmienkami
Stiahnuté 3x (58.73 kB)
Aplikácia je vrátane zdrojových kódov v jazyku Python


